
- 版本ocr软件下载(图像OCR文字识别软件)
- 分类系统工具
- 星级
- 语言简体中文
- 时间2024-07-08
- 系统Win10/Win8/Win7
应用截图
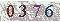
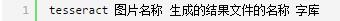








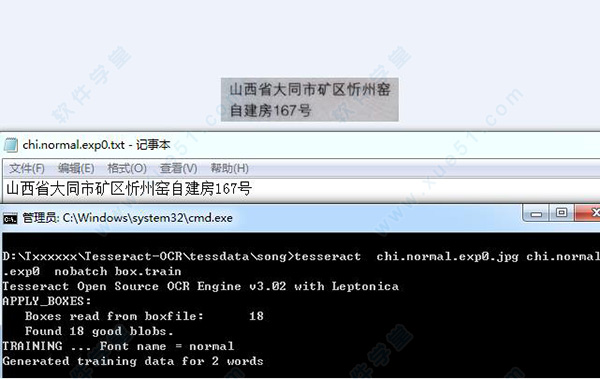
应用描述
Tesseract OCR是一个免费的开源OCR引擎,可以将印刷体文字转换为计算机可编辑和可搜索的文本。它最初由Hewlett-Packard实验室开发,现在由Google维护和支持。该软件使用C ++编写,支持多种操作系统,包括Windows,Mac和Linux。Tesseract OCR可以识别多种语言,包括英语,中文,日语,韩语,阿拉伯语等,支持多种文本格式的输出,例如PDF,HTML和TXT。它可以处理各种字体和文字大小,并且可以处理不同方向的文字,例如从左到右,从右到左,从上到下和从下到上。此外,它还可以自动检测和修复文本中的错误,例如删除不必要的字符或更正拼写错误。使用Tesseract OCR非常简单。用户可以将需要转换的图像或PDF文件拖放到软件界面上,或使用命令行界面执行转换操作。用户可以根据自己的需要选择不同的输出格式和语言,并在转换前对转换参数进行设置。转换完成后,结果将以文本文件或PDF文件的形式保存在指定的目录中。Tesseract OCR被广泛应用于各种领域,例如数字化图书馆,自然语言处理,人工智能和机器学习等。它可以帮助用户节省大量时间和劳动力,提高工作效率和准确性。在数字化时代,Tesseract OCR是一种非常有用的工具,可以帮助人们更轻松地管理和处理大量的文本信息。
安装教程
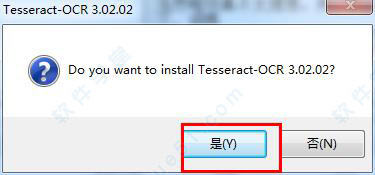
1、在本站下载解压好安装包,双击运行“tesseract-ocr-setup-3.02.02.exe”tesseract ocr 中文版开始安装软件,点击“是”。
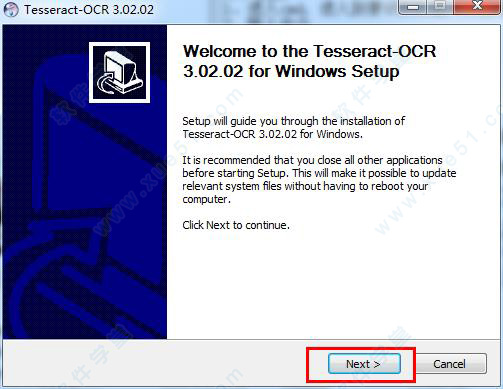
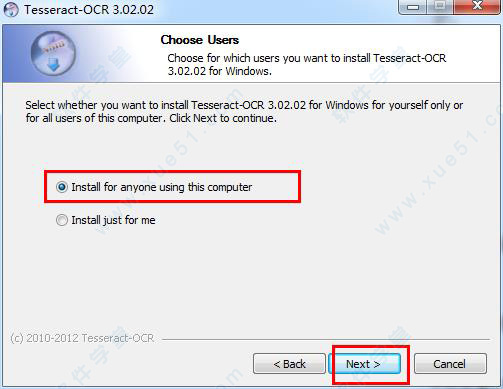
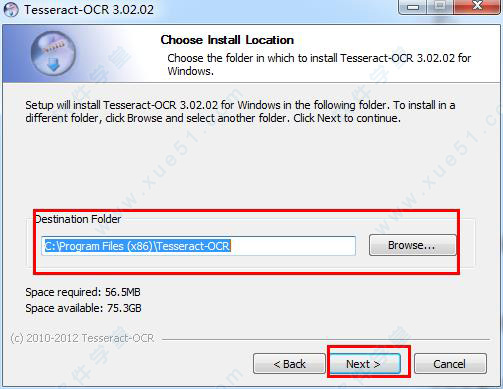
2、根据下面图片上的教程,连续点击“next”。
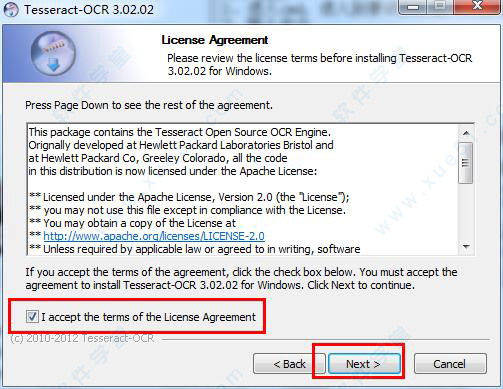
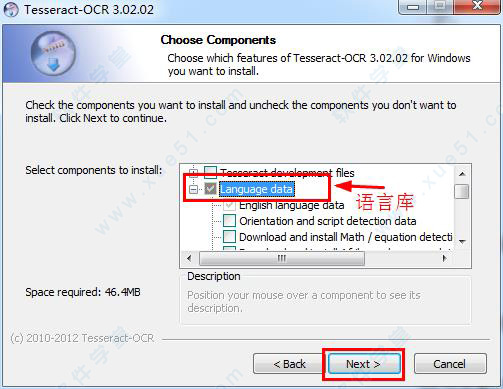
3、到了语言库的选择,你要使用到哪种语言就勾选哪种,默认是一种都不勾选,然后点击“next”。
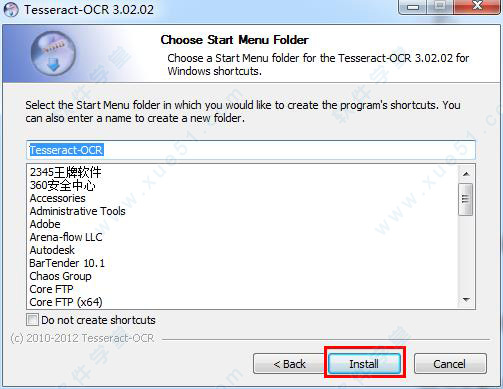
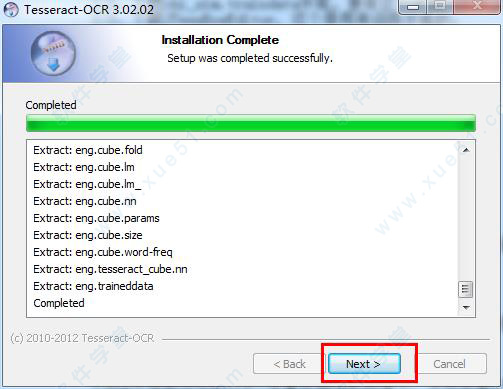
4、然后点击“install”,开始正式安装,安装完成之后点击“next”。
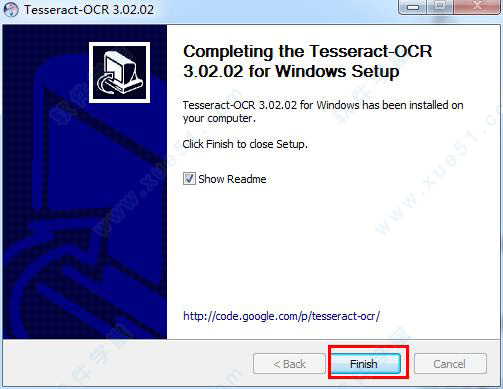
5、全部安装完成点击“finish”,tesseract ocr 中文版安装结束。
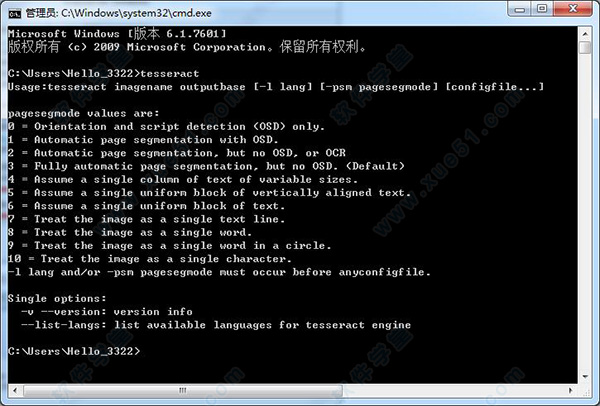
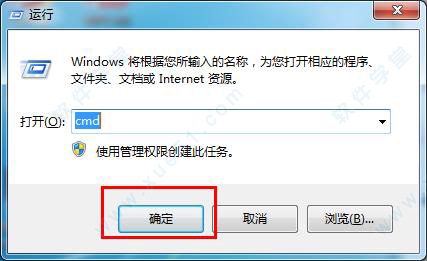
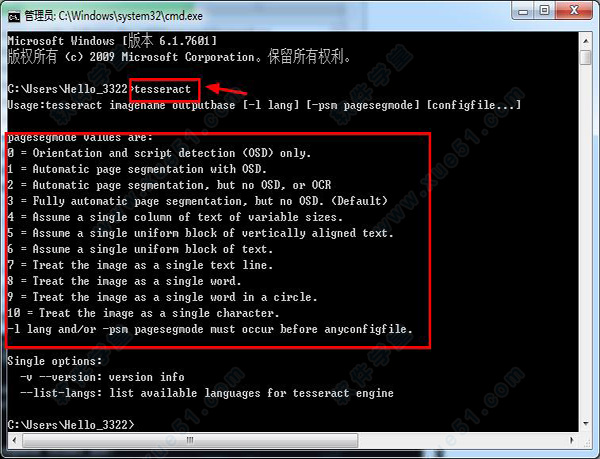
6、检验是否安装成功,运行(win+R)—输入“cmd”—输入“tesseract”,然后会出现下图所示的的情况那就是安装成功了。
使用教程
基本使用介绍
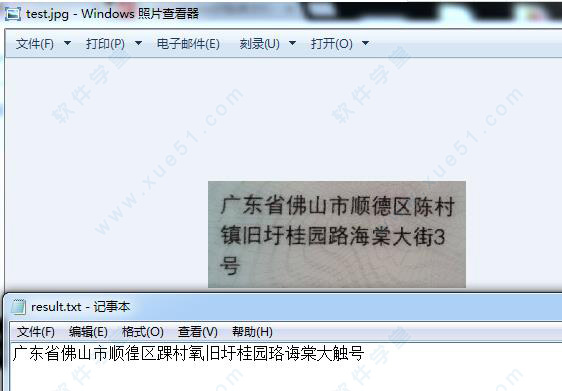
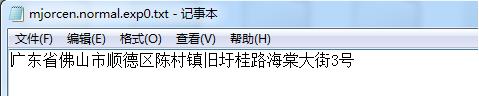
1、我准备了一张验证码1.jpg放置在D盘的根目录下,验证码图:
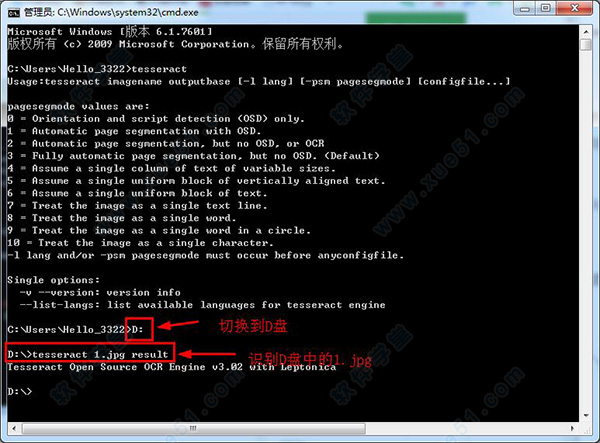
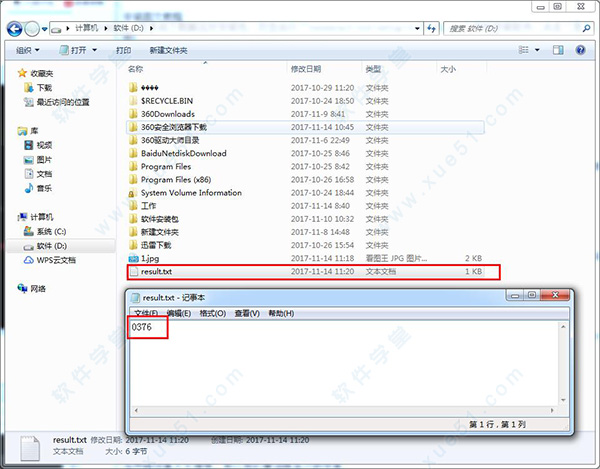
2、然后输入“D:”,回车,输入“tesseract 1.jpg result”,意思为:识别D盘中1.jpg图片中的内容,将结果输出到result.txt的文件中。
3、结果如图说是:
Tesseract-OCR识别中文与训练字库使用介绍
一、准备工作
1、下载引擎,注意要3.0以上才支持中文哦,按照提示安装就行。
2、下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到项目的tessdata文件夹里面。
3、下载jTessBoxEditor,这个是用来训练字库的。
以上的几个在百度都能找到下载,就不详细讲了。
二、识别
1、进入cmd,进入到要识别的图片的路径下。
2、输入命令
例如我的图片识别就是:
识别完后会生成result.txt文件
当然啦效果不太理想。所以我们要训练自己的字库。
三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
box文件和对应的tif一定要在相同的目录下,不然后面打不开。
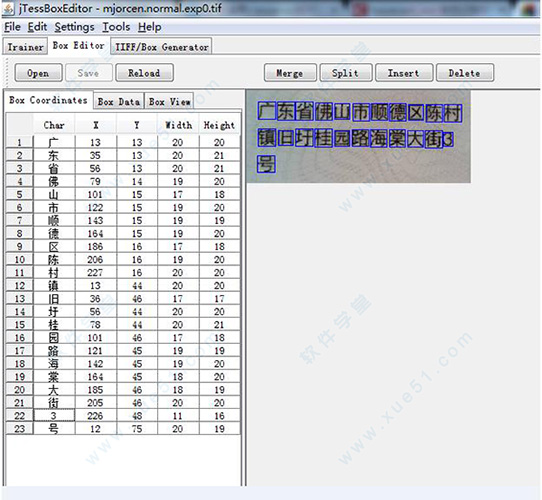
3、打开jTessBoxEditor矫正错误并训练
打开train.bat
找到tif图,打开,并校正。
4、训练。
只要在命令行输入命令即可。
在这我明明已经矫正好了,但是还是有1个字符不能识别出来,报的错跟实际上完全没有相关性,不知道是不是bug,到后面的结果就是“园”字没有识别出来。
先不管,毕竟只有一个样本。
新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
继续敲命令
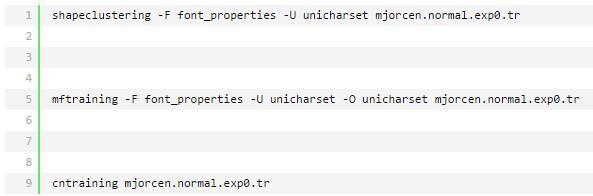
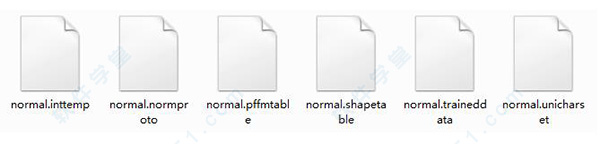
最后会生成五个文件,把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
如图:
命令行输入,合并五个文件:
得到训练好的字库。
四、测试
1、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
2、识别命令:
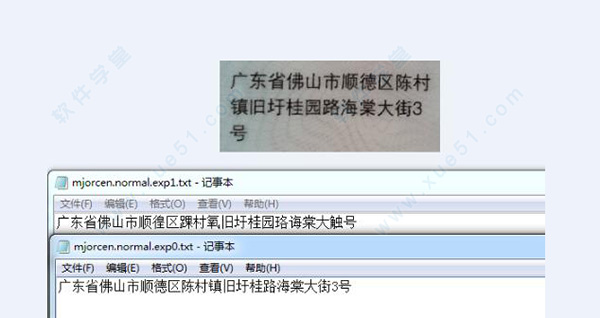
3、效果
对比:
总结:肯定要自己训练过后的字库识别效果好,接下来要把整个项目弄进android,还要研究怎么将多个字库合并成一个字库,因为我不可能一次训练完所有的图片文字的。到时候有什么成果了再分享博文。希望大家可以点赞!谢谢。
更新:没有错误的话命令行的提示应该是这样的
附录
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract 1.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract 1.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdataconfigs 和 tessdatatessconfigs 目录下的文件名
更新说明
其他信息
暂无

































相关阅读
查看更多





热门文章
-
 逆水寒pc怎么导入捏脸二维码(逆水寒捏脸二维码导入不了)
逆水寒pc怎么导入捏脸二维码(逆水寒捏脸二维码导入不了)
游戏资讯 2024-10-14
-
 金铲铲之战炼金狼怎么配装备(金铲铲之战双城之战炼金狼人阵容搭配攻略)
金铲铲之战炼金狼怎么配装备(金铲铲之战双城之战炼金狼人阵容搭配攻略)
游戏资讯 2024-10-14
-
 光遇奇妙之旅任务攻略(光遇奇妙之旅的爱心怎么获得光遇爱心获得方法介绍)
光遇奇妙之旅任务攻略(光遇奇妙之旅的爱心怎么获得光遇爱心获得方法介绍)
游戏资讯 2024-10-14
-
 lol游戏来了读条页面进的慢(英雄联盟进入游戏加载的时候特别慢是什么原因 )
lol游戏来了读条页面进的慢(英雄联盟进入游戏加载的时候特别慢是什么原因 )
游戏资讯 2024-10-14
-
 和平精英游戏周报哪里分享(和平精英怎么生成精英战报)
和平精英游戏周报哪里分享(和平精英怎么生成精英战报)
游戏资讯 2024-10-09
热门
游戏 应用
-
 劲舞时代
劲舞时代
网易精品正版授权,社交音舞巨作
下载 -
 节奏大师
节奏大师
一流节奏手感,一歌多玩的难度进阶
下载 -
 顽鹿竞技
顽鹿竞技
Onelap全新移动版
下载 -
 lol手游国际服
lol手游国际服
一款公平竞技手游
下载 -
 LOL手游日服
LOL手游日服
英雄联盟手游日服官方版本
下载 -
 鸿图之下
鸿图之下
腾讯旗舰沙盘战略
下载 -
 300大作战
300大作战
Vsinger全员联动
下载 -
 小米超神
小米超神
指尖上的经典MOBA
下载 -
 浮生为卿歌
浮生为卿歌
一曲倾心 情醉浮生
下载 -
 原神
原神
米哈游全新开放世界
下载 -
 猫和老鼠
猫和老鼠
欢乐互动 正版授权
下载 -
 乱斗西游2
乱斗西游2
灵力战宠,倾力助阵
下载 -
 天涯明月刀
天涯明月刀
高沉浸感国风大世界手游
下载 -
 梦幻西游
梦幻西游
全新敦煌资料片上线
下载 -
 阴阳师
阴阳师
无套路妖怪对战卡牌
下载 -
 和平精英
和平精英
极限追猎
下载 -
 王者荣耀
王者荣耀
新版本【峡谷探秘】
下载














